(Image Source: Google, Android)
Google’s Gemini is a revolutionary AI model designed to enhance the Android development experience by integrating AI across every stage of the development lifecycle within Android Studio. Introduced as an AI-powered coding companion, Gemini aims to accelerate the development of high-quality Android apps by providing developers with advanced tools and features that streamline their workflow.
Gemini’s integration of multimodal AI into Android Studio marks a significant milestone in leveraging AI to improve productivity and efficiency in app development. By offering features like code editing, design pattern implementation, and code refactoring, Gemini goes beyond mere guidance, allowing developers to focus more on writing code and less on tedious tasks.
By integrating multimodal capabilities, Gemini AI can now process screenshots, UI sketches, and wireframes, offering real-time suggestions and code generation based on these inputs. This update significantly reduces development time, enhances debugging processes, and enables faster UI/UX prototyping.
With AI playing an increasing role in software development, this multimodal support in Android Studio sets a new standard for intelligent coding assistants. Let’s explore how this works and why it’s a game changer for Android developers.
What Are Multimodal Inputs in Gemini AI?
(Image Source: Android)
Multimodal inputs refer to an AI system’s ability to process and understand multiple types of input data, such as text, images, code, and speech, simultaneously. Instead of relying solely on text-based interactions, multimodal AI integrates different data formats to offer more context-aware and intelligent assistance.
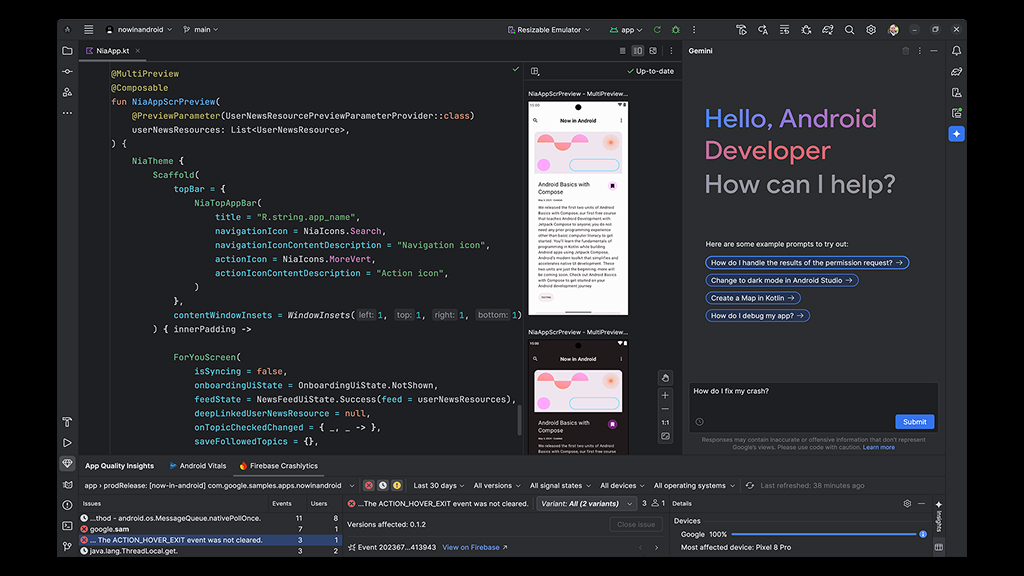
In Android Studio, Gemini’s multimodal capabilities are particularly useful for enhancing user interface (UI) design. It can auto-generate previews for UI elements using AI, simplifying the process of manually building mock data into UI components. This feature saves time and also improves the accuracy and consistency of UI designs.
Key Features of Gemini’s Multimodal Support in Android Studio

Gemini AI’s multimodal support in Android Studio introduces several powerful features that enhance developer workflows:
1. Image Attachment
One of the groundbreaking features is its ability to process image attachments, introducing a new dimension of interaction for developers. They can now upload UI sketches, screenshots, wireframes, or even app layouts, allowing Gemini to analyze and provide context-aware suggestions.
How Does It Work?
- UI Design Assistance
Upload a wireframe or screenshot, and Gemini suggests XML layouts or Jetpack Compose components to match the design.
- Visual Debugging
Developers can attach screenshots of a broken UI, and Gemini identifies issues such as misaligned elements, accessibility concerns, or styling inconsistencies.
- Code Generation from Images
Based on an uploaded UI mockup, Gemini can generate frontend code, reducing manual effort.
2. Rapid UI Prototyping and Iteration
The Gemini AI in Android Studio revolutionizes UI prototyping and iteration by enabling developers to quickly transform design concepts into working code. With multimodal input support, including image-based interactions, developers can dramatically speed up the design-to-development workflow.
How Does It Work?
- Sketch-to-Code Conversion
Upload wireframes or UI sketches, and Gemini generates the corresponding Jetpack Compose or XML layout code.
- Instant Design Feedback
Gemini analyzes UI elements and suggests improvements in structure, responsiveness, and accessibility.
- Rapid Iteration
Developers can refine UI components based on AI-generated recommendations, making design adjustments in real-time without manual rework.
- Theme and Styling Assistance
Gemini can suggest Material Design guidelines, color schemes, and typography improvements to enhance UI consistency.
3. Diagram Explanation and Documentation
As Gemini AI in Android Studio now supports diagram interpretation and documentation, it makes it easier for developers to understand complex workflows, system architectures, and UI structures. With multimodal input processing Gemini AI will analyze and generate meaningful explanations or documentation.
How Does It Work?
- Diagram-to-Text Conversion
Upload a UML diagram, flowchart, or system architecture, and Gemini generates a detailed explanation of components and relationships.
- Code Documentation from Diagrams
Gemini converts architecture diagrams into structured documentation, improving project maintainability.
- Visual Debugging & Optimization
Developers can attach UI flow diagrams, and Gemini suggests optimizations for navigation, user experience, and performance.
- Automated API and Data Flow Explanations
Upload a database schema or API flow diagram, and Gemini generates descriptions, SQL queries, or REST API documentation.
This feature enhances team collaboration, improves code maintainability, and makes complex system design more accessible by bridging the gap between visual representations and structured documentation
4. UI Troubleshooting with AI-Powered Debugging
Gemini AI’s multimodal support brings advanced UI troubleshooting capabilities to Android Studio, helping developers quickly detect and resolve visual and layout issues. By analyzing screenshots, wireframes, and code, Gemini provides AI-powered debugging suggestions, reducing the time spent on manual UI fixes.
How Does It Work?
- Screenshot-Based Issue Detection
Upload a screenshot of a misaligned or broken UI, and Gemini identifies layout inconsistencies, overlapping elements, or missing constraints.
- Automated Fix Suggestions
Gemini suggests constraint changes, margin adjustments, or responsive design fixes based on Material Design guidelines.
- Accessibility Enhancements
AI detects contrast issues, missing alt text, and touch target problems, ensuring a more inclusive user experience.
- Live Debugging Assistance
Developers can highlight UI components, and Gemini provides real-time insights on styling, performance, and recommended best practices.
Comparing Gemini’s Multimodal Input Support to Other AI Assistants

When comparing Gemini’s multimodal input support to other AI assistants, it’s essential to consider how each model integrates multiple data types to enhance user interactions and applications. Here’s a comparison of Gemini with other notable AI assistants:
1. Multimodal Capabilities
- Gemini
It supports text and image inputs, allowing it to generate text-based responses that incorporate visual information. It is particularly useful in Android app development for enhancing UI design and code generation.
- ChatGPT 4
It also supports text and image inputs, enabling more nuanced and contextually relevant interactions. It is designed for a broader range of applications beyond app development.
- Microsoft Copilot
Offers multimodal capabilities through its integration with GPT-4 Turbo, enabling features like image generation and video analysis.
- Google Bard
Also supports multimodal search, generating images from text prompts and integrating with Google tools like Docs and Sheets.
2. Application Focus
- Gemini
Primarily focused on Android app development, providing features like code editing and UI design assistance.
- ChatGPT 4
General-purpose AI model with applications across various domains, including content creation and virtual assistance.
- Microsoft Copilot
Focused on general productivity and data science tasks, integrated with Microsoft 365 tools.
- Google Bard
General-purpose AI chatbot with applications in content creation and coding assistance across various Google tools.
Gemini’s multimodal input support is specifically tailored for Android app development, offering unique advantages in UI design and code generation. While other AI assistants provide broader applications and capabilities, Gemini’s focus on app development makes it a powerful tool for Android developers.
How Does Gemini’s Ability to Process Multiple Modalities Improve Content Generation?

Gemini’s ability to process multiple modalities significantly enhances content generation by allowing it to understand and integrate diverse data types such as text, images, audio, and video. This multimodal capability enables Gemini to generate more comprehensive and contextually relevant content.
For instance, it can analyze images to extract visual information and incorporate this understanding into text-based responses, creating richer and more engaging content. Additionally, Gemini can generate creative content like scripts or music inspired by visual or auditory inputs, expanding the possibilities for multimedia content creation and improving overall user interaction with AI-generated content.